Pausable pipelines
Today we are using Azure Functions to pause and restart pipelines on demand. This is very handy when a user must be added into the loop to confirm the go ahead of some process. Of course, you could replace the user with another function that runs automated checks or whatever else you fancy. A similar setup can be accomplished using Logic Apps or Power Automate but doing it this way puts us on the steering wheel. Sometimes, that's a good idea and sometimes not so much. Use your best judgement 😊. Of course, if you just want the code then you can find it in the Function Automate repo.
The system we are building consists of two API endppoints implemented as Azure functions. The first one, PausePipeline, stores metadata in Table storage and generates a token that can be used by the RestartPipeline endpoint. If the pipeline restart succeedes you will be greeted with a congratulations web.
I've made the functions as general as possible. This allows us to stop/start pipelines regardless of what tenant there are in or what data they need with a single App.
We will also make use of the code from previous posts to generate and send emails.
Pausing the pipeline
The first component we are considering is the function responsible for "pausing" the pipeline. It handles storing any metadata we need to restart the pipeline and the generation of the restart token. The core idea is to store the metadata together with the restart token in Table storage. The restart token will be used to programmatically start the second pipeline and retrieve the metadata.
This first function, PausePipeline, takes the following parameters in the incoming request:
factory_name: Name of the Data Factory where we have the second halve of the pipeline.resource_group: Resource group for the Data Factory.<pipeline_name: Name of the second pipeline.expiration_time: Number of seconds before the restart token expires.share_name: Share name where we keep the success website. In the current implementation the share needs to use the Azure Function's storage account.web_path: Path inshare_nameto the website.data: Additional data stored in a JSON object required by the second pipeline. The standardjson.dumpsfunction is used for serializing this prior to storage.
The code for the entry point is below:
All it's happening in this function is the extraction and validation of the
parameters described above. The get_pipeline_params and
get_notification_web_params functions take care of this. Then we repackage
everything for its insertion in Table storage using prepare_pipeline_data.
The other important aspect to the PausePipeline code is the generation of a random token that is stored in the Table entry and returned in the outgoing request. The token has 64 bytes which should be enough to fence off attacks and avoid key collisions.
The restart API won't won't be using authentication. If you have the token you can trigger the pipeline. It is crucial that it is both random and long. Additionally, we have given it an expiration time to reduce our chances further.
Since we are working with an unauthenticated API further protection measures would be highly advisable.
With the code out of the way we can proceed to build the pipeline. The image below shows the activities that have to be placed at the end of the pipeline we want to stop.
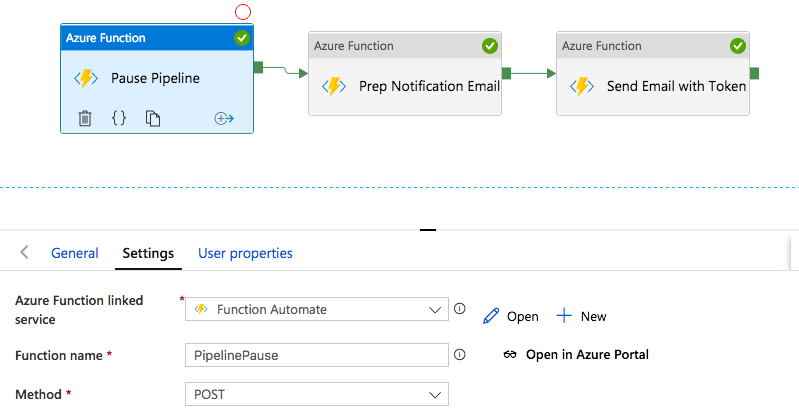
The first activity handles calling the PausePipeline endpoint, which returns the restart token. The latter we will embedded into our email using the procedure described on a previous FunctionAutomate post. The POST request must have all the above parameters and it will look something like:
The data field consists of all the data you want to send to the second
pipeline. It should take the shape of an object that must be serializable using
Python's json.dumps.
The email template is just an HTML page with an embedded link to call the RestartPipeline API endpoint.
Restarting the pipeline
Clicking on the restart link sends a request to the RestartPipeline endpoint which trigger the second pipeline. If everything works you will be presented with the success page. The second part of the split pipeline will look similar to:
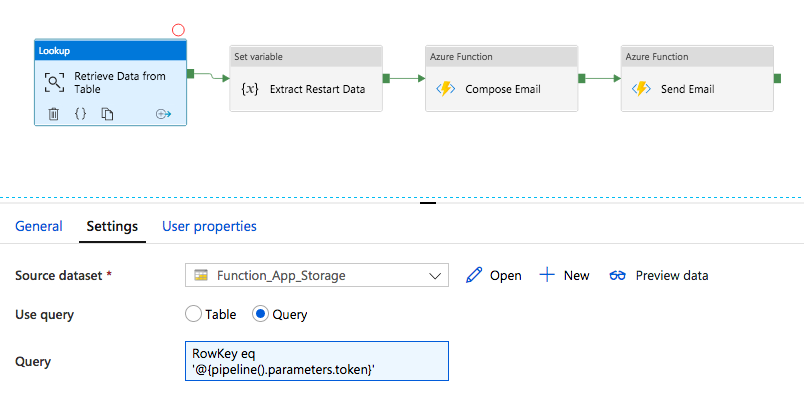
In first place, we search table storage for row corresponding to received token. Once that is retrieved, we store the data field into a variable to make it more convenient to manipulate. The dynamic content for setting the variable is as follows:
@activity('Retrieve Data from Table').output.firstRow.data
The last two steps should be replaced with the actual pipeline that needs to
get restarted. In this example they are just sending a templated email using
the data that was passed around from the first pipeline. Remember the data
needs to be deserialized using the ADF json function. This will turn it
again into a JSON-like object.
@{json(variables('restart_data')).template_file}
The only thing left to do is check the code for the RestartPipeline endpoint. Here is the main.
First we check the token exists in Table storage, if it doesn't we respond with a 500 error. This is particularly important because the endpoint has no authentication.
Next we check the token hasn't expired or has already been used to trigger it's associated run. Otherwise we return a 500 again. All that is left now is to: trigger the pipeline, mark the run as acted_upon and reply with the success webpage.
The code to restart the pipeline is straightforward once you figure out the API for the SDK. The most remarkable part is how we are able to pass python variables as parameters for the pipeline. Since I wanted the code to remain general we only need to pass the token. All other data required by the pipeline should be stored in the run entry in Table storage and is not manipulated in any way by the endpoint.
Outro
Now you can stop and restart pipeline in a fully programmatic way. By taking this route you have total control of how and when pipelines are triggered using a unified API that works across tenants and resource groups and at a very low cost. It also affords the possibility of doing other cool stuff like prepopulating the table with pipelines that we will want to have eventually run on demand.
As usual all the code is available in the Function Automate repo Thanks for reading and stayed tune!